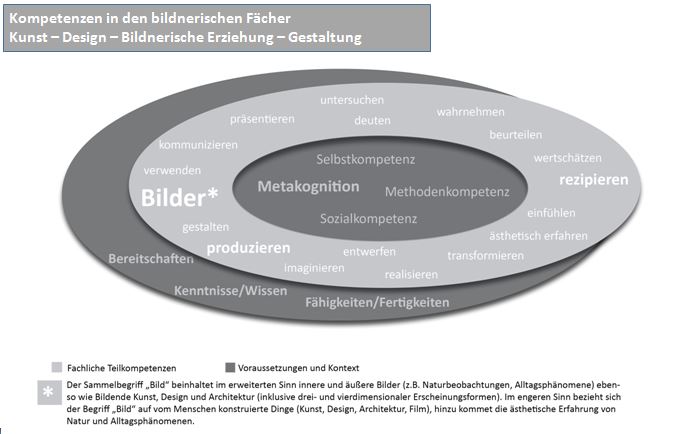
Vom 7. bis 9. Mai trafen sich das Consortium CEFR_VL (in Kooperation mit ENViL) zur Frühjahrstagung an der Universität Augsburg. Das Treffen stand – neben der Arbeit an der gemeinsamen Publikation – ganz im Zeichen der Feinabstimmung des Kompetenzstrukturmodells: Drei verschiedene Zugangsweisen galt es in einer Visualisierung zu integrieren. Dies gelang: Das Modell betont nun einerseits das Verhältnis von Kenntnissen/Wissen (knowledge), Fähigkeiten/Fertigkeiten (skills) und Haltungen (attitudes). Darüber hinaus zeigt es das Verhältnis von Selbst-, Fach-, Sozial- und Methodenkompetenz auf. Zentralstes Moment des Modells ist jedoch die Darstellung der fachspezifischen Kompetenzen mit der Rahmung durch Metakognition. Dieses Modell ist nun das Herzstück des zukünftigen „Europäischen Referenzrahmen für Visual Literacy“.